



Kubernetes was supposed to simplify infrastructure. For many startups, it did the opposite.
As engineering teams scale, Kubernetes environments become harder to manage: deployments grow fragile, observability becomes noisy, and infrastructure issues begin slowing product delivery. Developers spend more time troubleshooting clusters than shipping features.
The problem is not Kubernetes itself. The problem is operational complexity.
Most application teams are now responsible for networking, scaling, security, CI/CD pipelines, and cloud optimization, often without formal Kubernetes training. This is where structured DevOps services in USA can help teams bring governance, automation, and reliability into their Kubernetes operations.
If CI/CD itself is becoming a bottleneck, read our guide on what a CI/CD pipeline is and how it helps CTOs reduce slow releases.
In 2026, successful teams are not necessarily the ones with the biggest DevOps budgets. They are the ones with operational discipline, strong k8s best practices, and clear signals for when external Kubernetes expertise is needed.
Key takeaways:
- 82% of organizations now run Kubernetes in production, yet 45% of all K8s incidents still stem from misconfigurations.
- The most dangerous K8s problems are over-privileged pods, missing resource limits, default RBAC.
- Resource management mistakes quietly increase cloud costs and deployment instability.
- A lean observability stack (Prometheus + Grafana + Loki) covers 80% of real-world production needs.
- Self-managed Kubernetes is a liability for teams without dedicated SRE/platform engineering resources.
- A Kubernetes managed service is often cheaper once you factor in hidden engineering hours.
- If your on-call rotation is constantly firefighting K8s alerts, it's time to bring in a specialist.
Why Is Kubernetes So Hard to Manage for Application Teams?
Kubernetes is difficult because it combines infrastructure, networking, scaling, security, deployment automation, and observability into a single operational layer.
Most application teams were never trained to manage distributed systems at this depth.
For US startup teams specifically, three compounding factors make Kubernetes management 2026 especially painful:
- No formal K8s training. Most DevOps engineers learned Kubernetes on the job, absorbing tribal knowledge that doesn’t transfer when team members leave.
- Rapid cluster sprawl. What starts as one cluster becomes five, across multiple cloud regions and providers, each with different configurations.
The result: teams that are technically running Kubernetes, but operationally flying blind.
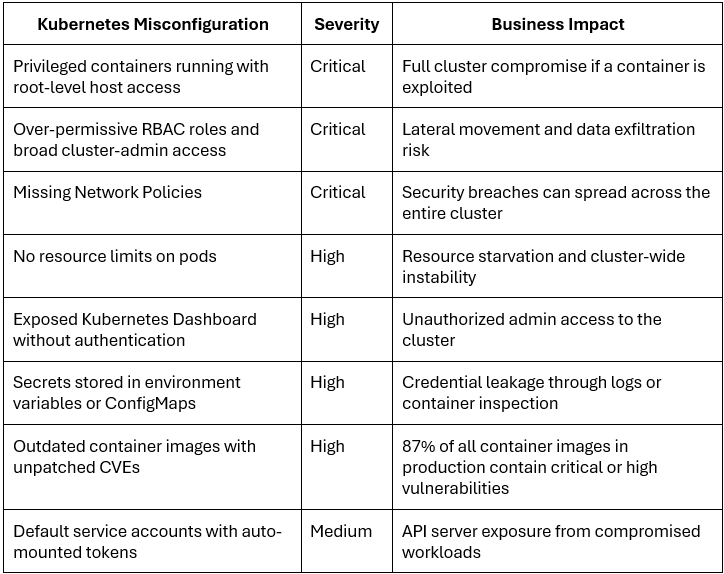
What Are the Most Common Kubernetes Misconfigurations?

Most Kubernetes failures come from preventable configuration issues involving security, networking, scaling, observability, and resource management.
Here are the most common Kubernetes misconfigurations teams still struggle with in 2026:
Also read: Struggling with Deployments, Cloud Costs, and Security? Here's How DevOps Solves All Three
How Do Resource Limits, Requests, HPA, and VPA Actually Work?
Resource mismanagement is where most startup K8s clusters quietly waste thousands of dollars per month and where most outages originate.
1. Requests vs Limits: What’s the Difference?
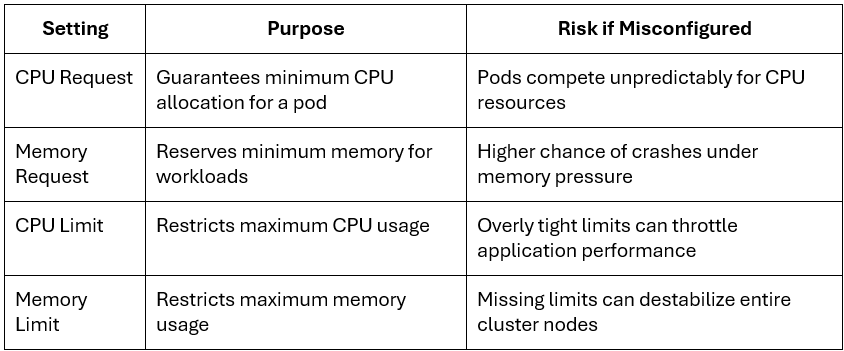
The practical rule for k8s best practices: Always set requests. Be careful with limits: overly tight CPU limits cause unexpected throttling that looks like application slowness, not infrastructure failure.
2. HPA (Horizontal Pod Autoscaler)
HPA automatically adds or removes pods based on traffic or resource usage like CPU and memory. It works best for APIs, Web applications & Stateless services.
A common production mistake is setting: minReplicas: 1. It creates a single point of failure. For production services, a safer baseline is: minReplicas: 2
3. VPA (Vertical Pod Autoscaler)
VPA adjusts CPU and memory allocations based on actual usage. It is useful when horizontal scaling is not practical, but it needs caution. In auto mode, VPA may restart pods to apply changes, which can affect production stability.
The practical rule: use HPA for traffic-based scaling, use VPA carefully for resource tuning, and test both before production rollout.

4. The OSSPL Resource Governance Framework
While working with US startups at OpenSpace Services, we follow a three-phase approach to K8s resource management:
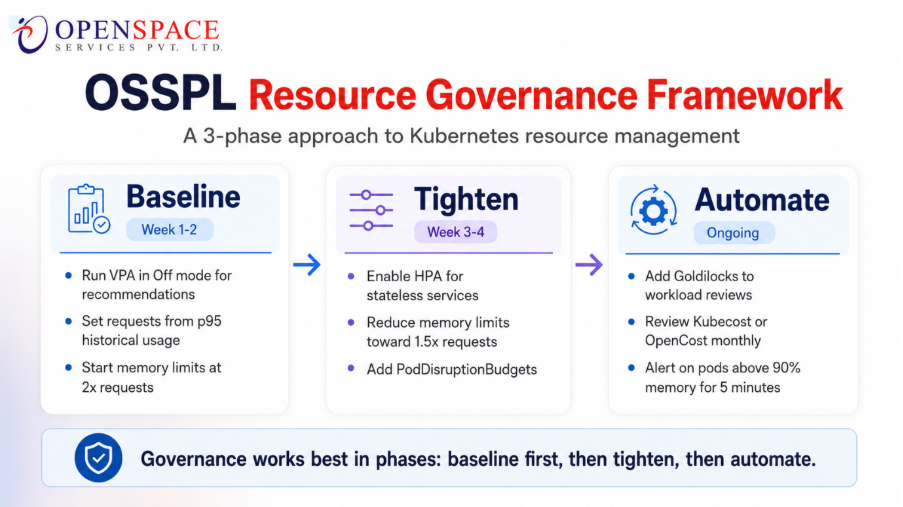
Phase 1: Baseline (Week 1-2):
- Deploy VPA in “Off” mode to collect recommendations
- Set requests based on p95 historical usage
- Set memory limits at 2x requests for initial safety margin
Phase 2: Tighten (Week 3-4):
- Enable HPA for stateless services (target 70% CPU utilization)
- Reduce memory limits toward 1.5x requests using VPA recommendations
- Add
PodDisruptionBudgetsfor all production Deployments
Phase 3: Automate (Ongoing):
- Integrate
Goldilocks(VPA recommendations in CI) for new workload reviews - Schedule monthly resource review with
KubecostorOpenCostreports - Alert on pods running at >90% of memory limits for more than 5 minutes
What Does a Proper Kubernetes Observability Stack Look Like?


OpenSpace Services' DevOps Managed Services include monitoring, logging, and observability implementation, tracking application performance and infrastructure health 24/7.
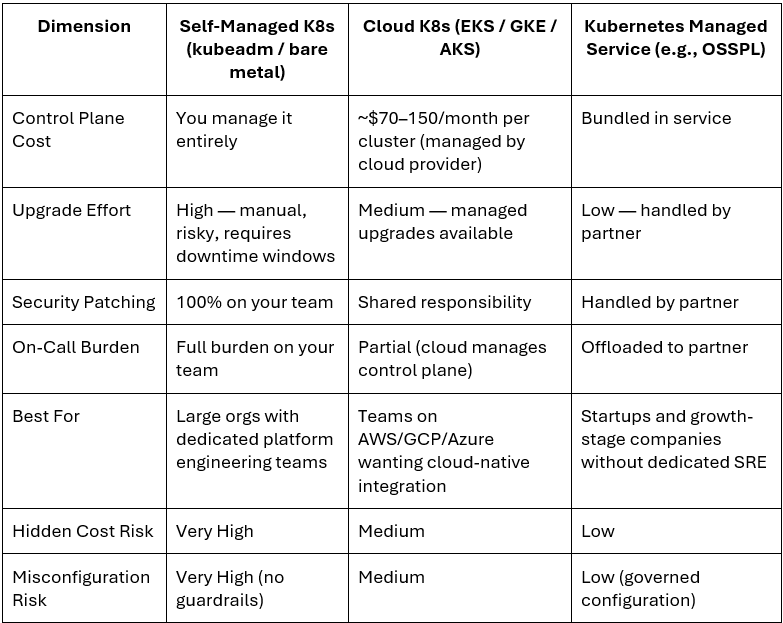
Self-Managed K8s vs. EKS/GKE/AKS vs. Kubernetes Managed Service: Which Is Right for You?

What Are the Warning Signs That Your Team Needs K8s Expert Help?
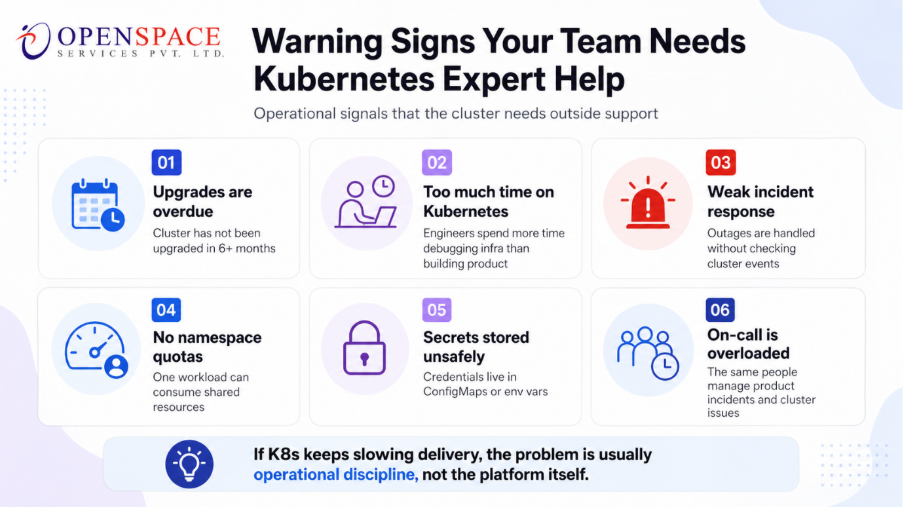
1. Cluster upgrades are overdue
If your cluster has not been upgraded in 6+ months, you are likely running behind multiple Kubernetes minor releases. This increases exposure to known security vulnerabilities and compatibility issues.
2. Engineers spend more time on Kubernetes than product work
When debugging infrastructure becomes a daily activity, Kubernetes is no longer enabling velocity. It is blocking it.
3. Incident response does not include kubectl get events
If your team is not using basic cluster event inspection during outages, incident diagnosis is incomplete and slower than necessary.
4. No resource quotas at namespace level
Without quotas, a single workload can consume shared cluster resources and degrade all other services.
5. Secrets stored in ConfigMaps or environment variables
This is one of the most common Kubernetes misconfigurations and one of the highest security risks. It increases the chance of credential leakage.
7. On-call includes both product and cluster management
If your team is unsure whether this should sit with DevOps, SRE, or a platform team, this breakdown of Platform Engineering vs DevOps vs SRE will help clarify ownership.
When the same engineers handle product incidents and infrastructure-level cluster management, operational load becomes unsustainable. These responsibilities require different skill sets.
Final Thoughts
In 2026, Kubernetes is a standard production platform for most software companies. However, using Kubernetes and operating it well are very different. Most outages, security issues, and cloud cost overruns come from this gap.
Teams that succeed with Kubernetes typically:
- Instrument everything for visibility
- Keep configurations simple and well-governed
- Seek help when internal capacity or expertise is insufficient
If your team spends more time managing infrastructure than building product, the issue is not Kubernetes. It’s an operations strategy problem and it has a clear solution.
Ready to stop firefighting your Kubernetes cluster?
Explore OpenSpace Services’ DevOps services in USA to stabilize deployments, improve observability, strengthen Kubernetes security, and reduce infrastructure firefighting.
Book a Free DevOps Consulting Session with OpenSpace Services Today!
